Kernel Code Optimizations for Versal ACAP with Vitis
Feb 28, 2022
Introduction
Vitis is a unified software platform to develop embedded software and accelerated applications onto heterogeneous AMD platforms including FPGAs (Field Programmable Gate Array), SoCs (System on Chip), and Versal ACAPs. In this article, we briefly describe Vitis and then provide an overview of the key kernel optimizations to get the most of the silicon.
Vitis Flow
With Vitis, developers leverage the integration with high-level frameworks, develop in C, C++, or Python using accelerated libraries. Lower level, fine-grain control is also possible through RTL-based accelerators and low-level granular runtime APIs — In short, you can choose the amount of abstraction that suits you!

The fundamental basis of Vitis is a standard or custom platform for which the developer codes and it involves a host processor which can be on or off-chip. The developer then codes kernels that are compiled for either the adaptable engines or the AI engines that we will discuss below. Once the kernels are designed, Vitis links all the elements together, connecting these kernels to the platform while leveraging the dedicated network-on-chip connections found in Versal.
Kernel Software Development
In an initial phase, the system architects make key decisions about the overall application architecture by determining which functional software blocks should be mapped to device kernels, how much parallelism is needed, and how it should be delivered. There are 3 main hardware functional domains to map the software application (see below).
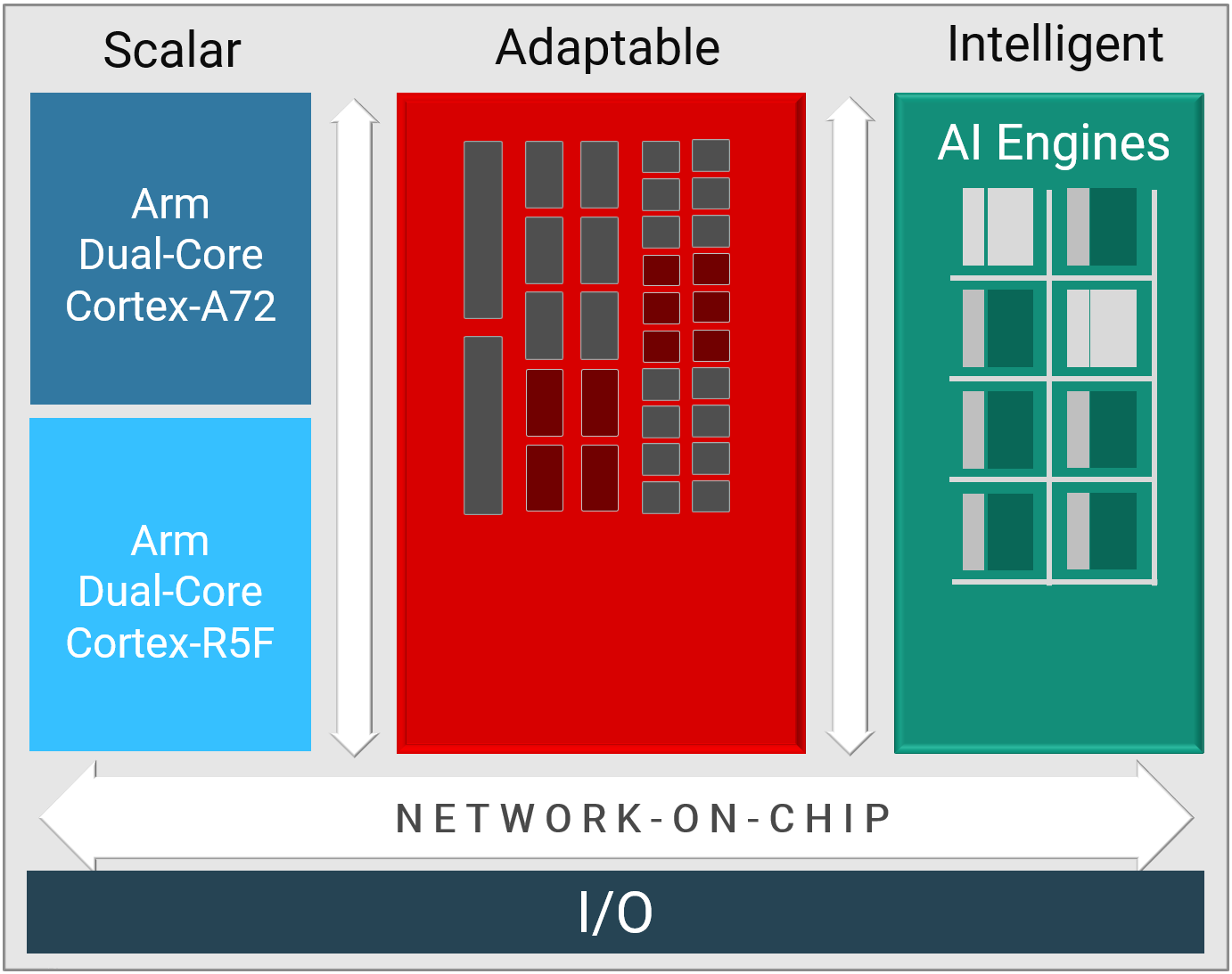
- The scalar engine processors are ideal for complex algorithms, decision making, or control software, tasks that sequence the overall application flow while leaving the compute-intensive task to the adaptable engines or the vector processors.
- These adaptable engines are suitable for irregular data structures, arbitrary precision data types, or bit level manipulations. This is akin to the classic FPGA fabric which is well suited for functions that require low latency or real-time operations.
- The vector processing with intelligent engines applies to domain specific applications with large amount of data parallelism. They guarantee high-compute density for complex math, convolutions, machine learning and imaging.
In a second phase, after choosing the most relevant engines, the developer codes for the scalar engines and the C++ kernels for the adaptable and AI engines. That latter task primarily involves structuring the C++ source code and applying compiler options to meet the performance target.
Kernel Code Optimizations
All three engines can be programmed in C/C++ and in this section, we discuss more specifically the design of C++ kernels targeting either the adaptable engines or the AI engines.
C++ for the Adaptable Engines
C++ is inherently sequential, but Vitis compiler can create hardware parallel structures through directives (pragmas) and specific coding styles. To understand how C++ tasks (C loops and functions) can execute in parallel, consider the conceptual example below in table 1. It illustrates how distinct functions can be executed in parallel onto the adaptable engines while still using portable, hence sequential in nature, C++. It is useful to understand that this task parallelism is implemented within the kernel itself and that the overlapped execution of the kernel by the Xilinx runtime (XRT) can also contribute to shortening the execution latency.

The Vitis C++ compiler can also create SIMD and vectors hardware structures, to execute multiple functions or instructions in parallel which can be combined with the pipelined operation for greater throughput.
As just seen above, on-chip memories play a key role in exerting parallelism. They are also critical to creating local on-chip copies of external, off-chip memory to improve performance. Once the data is copied, the processing starts and once finished, copied back to the external memory in what is known as a load-compute-store[i] pattern. By allowing the designer to size the on-chip buffers, Vitis can avoid cache hit misses that typically hinder performance for CPUs or GPU compute.
With adaptable engines, one crucial factor for performance is the choice of the most efficient data types. The designers typically opt for arbitrary sizes integers and fixed-point rather than floating-point. This latter type is also supported and even natively as in the new Versal DSP blocks for single-precision floating-point for multiplication and additions, but using floating-point typically results in more latency, more area, more power dissipation than fixed-point, integers, or arbitrary precision types.
Coding for the AI Engines
The Versal AI Core series offers newly specialized, high-density processing hardware that is also software programmable while also deterministic. The AI engines are organized as an array of interconnected tiles. Each processing tile contains 3 distinct compute units, a scalar RISC unit, and two 512-bit vector units for fixed and floating-point.
The inter-tile connections use a combination of dedicated AXI bus routing and direct connections to neighboring tiles. This exclusive (non-shared) interconnect between tiles guarantees deterministic performance and behavior and it is this abundance of local and distributed memories that helps create efficient designs without requiring memory caches that typically become bottlenecks for more classic types of processor units. These multi-precision engines provide an unprecedented high-compute density for vector-based algorithms while remaining highly programmable.
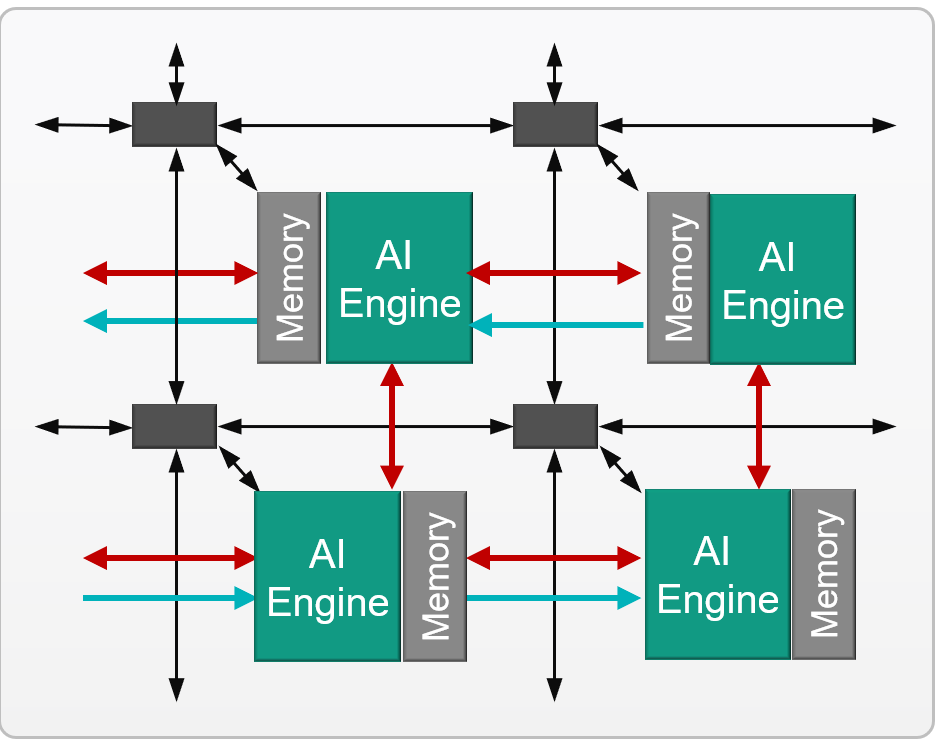
The figure above depicts four AI Engine tiles with their dedicated instruction and data memory interconnected to each other.
Given the AI engines high density, high throughput compute capabilities are ideally suited for highly optimized wireless applications such as radio, 5G, backhaul, and other high-performance DSP applications.
From the software perspective, designing for the AI Engines amounts to coding C++ with inline compiler directives (pragmas) and intrinsic instructions for of very-long instruction word (VLIW) processors with single instruction multiple data (SIMD) vector units. Data-level parallelism is achieved via these vector-level operations where multiple sets of data can be operated on a per-clock-cycle basis.
The kernel code is compiled using the AI Engine compiler (aiecompiler) and the C++ program implements hardware parallelism through:
- Vector registers and operators to allow multiple elements to be computed in parallel.
- Instruction level parallelism, multiple distinct VLIW instructions can be executed simultaneously in a single clock cycle.
- Multicore, using multiple tiles throughout the whole AI Engine array, where up to 400 AI Engines can execute in parallel!
The multicore (multi-kernel) programs are described as graphs with a data flow specification also expressed in C++. This called adaptive data flow (ADF) graph application specification is compiled alongside the kernels themselves and executed by the AI Engine compiler. The graph consists of nodes and edges. Nodes represent compute kernel functions, and edges represent data connections. The figure below shows the possible connections between AI engine tiles: memory interface connections and streaming interfaces.

With the AI engines, more tiles equate to more compute power, memory, and communication bandwidth. Through the AXI interconnect, the tiles can access other tiles and they can also access the adaptable engine's logic and memory.
Conclusion
Vitis allows end-to-end application acceleration using a purely software-defined flow that does not require FPGA design hardware expertise. Depending on the performance target goals, the designer will select the right engines to implement the amount of parallelism required: The Adaptable Engines are ideal for low latency and arbitrary precision math while the AI Engines will efficiently map vectorized data onto fixed- or floating-point operators.
