AI 推論の高速化
- 最も低いレイテンシの AI 推論
- アプリケーション全体を高速化
- 迅速なイノベーションを実現

最もレイテンシが低い AI 推論

高スループットまたは低いレイテンシ
高バッチサイズを使用してスループットを達成。処理前にすべての入力の準備ができるまで待たなければならず、必然的にレイテンシが大きくなります。
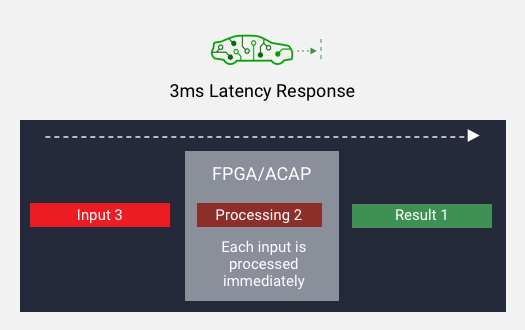
高スループットかつ低レイテンシ
小さいバッチ サイズを使用してスループットを達成します。各入力の準備ができ次第、処理を開始できるため、結果として低レイテンシを実現できます。
アプリケーション全体を高速化
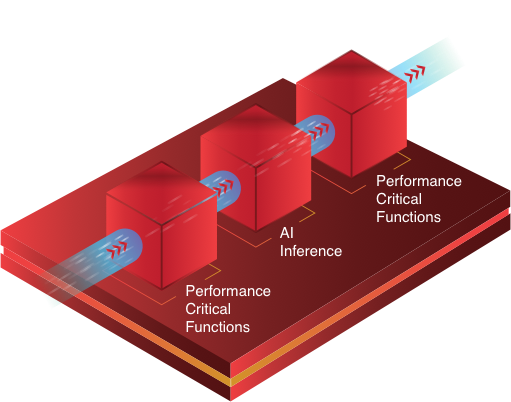
カスタム アクセラレータを動的アーキテクチャのシリコン デバイスに密接結合することで、AI 推論とその他の性能重視機能の両方に対して最適化されたハードウェア アクセラレーションが可能になります。
GPU のような固定アーキテクチャの AI アクセラレータを大幅に上回るアプリケーション全体の性能向上が可能です。GPU の場合は、その他の性能重視機能がカスタム ハードウェア アクセラレーションの性能や効率性の恩恵を受けることなく、ソフトウェアで実行されます。

迅速なイノベーションを実現
AI モデルは急速に進化している
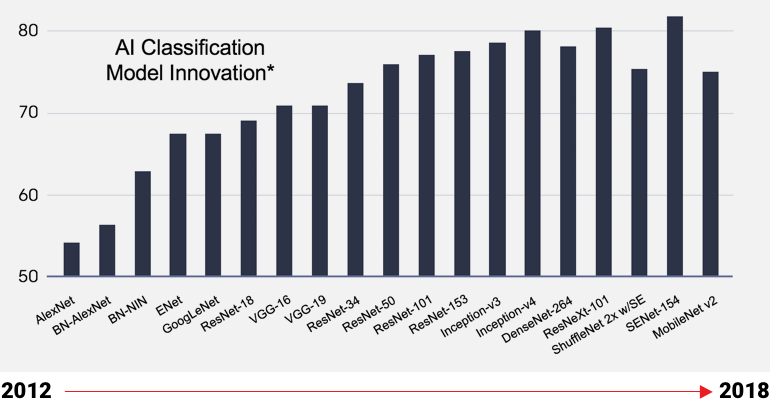
適応型のシリコンはドメイン固有アーキテクチャ (DSA) の更新を可能にし、
シリコンを新しくしなくても、常に最新の AI モデルに最適化できます。

固定のシリコン デバイスは開発サイクルが長いため、最新モデルに最適化されません。

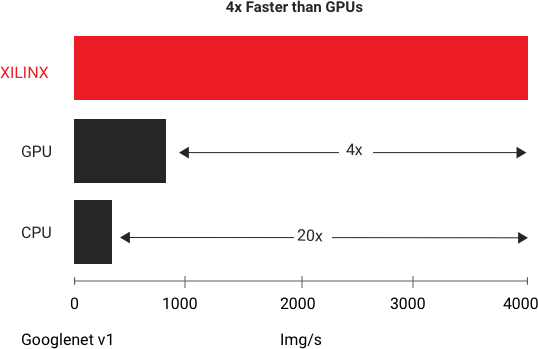
データセンターの Vitis AI
AMD は最も低いレイテンシで最高のスループットを実現します。GoogleNet V1 で実行した一般的なベンチマーク テストによると、AMD Alveo U250 プラットフォーム は、リアルタイム推論で最も高速な GPU の 4 倍のスループット性能を達成しています。詳細はホワイトペーパーでご覧ください。『AMD Alveo アクセラレータカードを使用した DNN の高速化』(日本語版)
エッジの Vitis AI
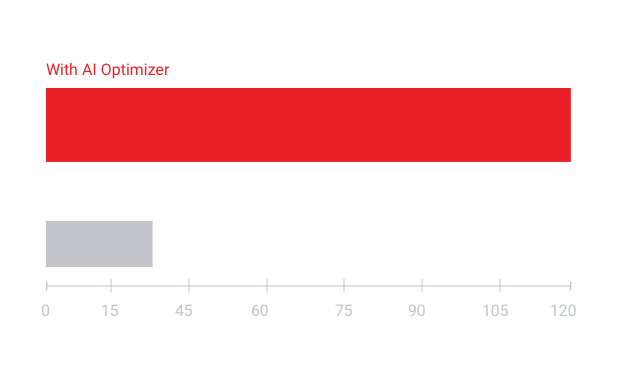
Vitis AI オプティマイザー技術により、優れた AI 推論性能を実現
- 5 ~ 50 倍のネットワーク性能最適化
- フレームレート (FPS) を向上、消費電力を削減
最適化/高速化コンパイラ ツール
- Tensorflow および Caffe のネットワークをサポート
- 最適化済みの AMD Vitis ランタイムにネットワークをコンパイル